|
Phalanx
Development
|
|
Phalanx
Development
|
Phalanx is a complex package that make heavy use of the C++ templating mechanism. We recommend that users of the Phalanx package first familiarize themselves with C++ templates. An excellent reference is "C++ Templates: The Complete Guide" by Vandevoorde and Josuttis, 2003. While users do not need to understand template metaprogramming to use Phalanx, the concepts underlying many operations in Phalanx can be found in "C++ Template Metaprogramming" by Abrahams and Gurtovoy, 2004 and the Boost template metaprogramming library (MPL).
Once Phalanx is integrated into a code by a template savvy developer, the only operation application users should perform is to extend the evaluation routines to new equations and new models by adding new Evaluators. We realize that application developers and application users typically have distictly different skill sets. Much design work has been invested in making the Evaluator implementation very clean and as template free as possible. Therefore, users of the code who only write new Evaluators DO NOT need to know templates.
Users should then learn the nomeclature used in the package defined in the Phalanx Domain Model.
The main concept of Phalanx is to evaluate fields typically for solving PDEs (although it is not limited to this). We demonstrate the integration process using the simple example found in phalanx/example/MultiDimensionalArray. Suppose that we want to solve the heat equation over the physical space 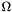 :
:
![\[ \nabla \cdot (-k \nabla T) + s = 0 \]](form_5.png)
where 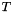 is the temparature (and our degree of freedom),
is the temparature (and our degree of freedom), 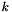 is the thermal conductivity, and
is the thermal conductivity, and 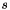 is a nonlinear source term. We pose this in terms of a conservation law system:
is a nonlinear source term. We pose this in terms of a conservation law system:
![\[ \nabla \cdot (\mathbf{q}) + s = 0 \]](form_9.png)
where 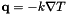 is the heat flux. The specific discretization technique whether finite element (FE) or finite volume (FV) will ask for
is the heat flux. The specific discretization technique whether finite element (FE) or finite volume (FV) will ask for 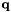 and at points on the cell. Phalanx will evaluate and at those points and return them to the discretization driver.
and at points on the cell. Phalanx will evaluate and at those points and return them to the discretization driver.
Using finite elements, we pose the problem in variational form: Find 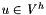 and
and 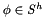 such that:
such that:
![\[ - \int_{\Omega} \nabla \phi \cdot \mathbf{q} d\Omega + \int_{\Gamma} \phi \mathbf{n} \cdot \mathbf{q} + \int_{\Omega} \phi s d\Omega = 0 \]](form_14.png)
Phalanx will evaluate and at the quadrature points of the cells and pass them off to the integrator such as Intrepid.
This is a trivial example, but the dependency chains can grow quite complex if performing something such as a chemically reacting flow calculation coupled to Navier-Stokes and energy conservation.
Follow the steps below to integrate Phalanx into your application. The example code shown in the steps comes from the energy flux example in the directory "phalanx/example/EnergyFlux". Note that many classes are named with the word "My" such as MyWorkset, MyTraits, and MyFactory traits. Any object that starts with the word "My" denotes that this is a user defined class. The user must implement this class specific to their application. All Evaluator derived objects are additionally implemented by the user even though they do not follow the convention of starting with the word "My".
Cell
Partial differential equations are solved in a domain. This domain is discretized into cells (also called elements for the finite element method). This library assumes that the block of cells being iterated over is of the same type! If different evaluators (i.e. different material properties) are required in different blocks of cells, a new FieldMangager must be used for each unique block of elements. This is required for efficiency.
Parallel and Serial Architectures
Phalanx can be used on both serial and multi-processor architectures. The library is designed to perform "local" evalautions on a "local" set of cells. The term local means that all cell and field data required for an evaluation is on the processor that the evaluation is executed. So for parallel runs, the cells are distributed over the processors and a FieldManager is built on each processor to evaluate only the cells that are assigned to that processor. If there is any data distributed to another processor that is required for the evaluation, the user must handle pulling that information on to the evaluation processor. The design of Phalanx will also allow for users to take advantage of multi-core architectures through a variety of implementations.
Workset
For performance and memory limitations, the evaluation of fields can be divided into worksets. While Phalanx does not require the use of worksets, we recomend their use for controlling the memory footprint (this can be important when offloading the kernels onto an accelerator and even for host node memory). The goal of using worksets is to fit all the required fields into the processor cache so that an evaluation is not slowed down by paging memory. Suppose we have a cell-based discretization with 2020 cells to evaluate on a 4 node machine. We might distribute the load so that 505 cells are on each MPI processor. Now the user must figure out the workset size. This is the number of cells to per evaluation call so that the field memory will fit into cache. If we have 505 cells on a processor, suppose we find that only 50 cells at a time will fit into cache. Then we will create a FieldManager with a size of 50 cells. This number is specified in the construction of data layouts. During the call to postRegistrationSetup(), the FieldManager will allocate workspace storage for all fields relevant to the evaluation.
For our example, there will be 11 worksets. The first 10 worksets will have the 50 cell maximum and the final workset will have the 5 remaining cells. The evaluation routine is called for each workset, where workset information can be passed in through the evaluate call:
Note that the call to evaluateFields() takes a workset data object in this example. The field_manager is templated on a traits class that allows the user to define the actual object passed into the evaluatFields call. This does not have to be a workset_data object but can be any class or struct the user defines (even void).
Note that you do not have to use the workset idea. In this cell-based discretization example, one could just evaluate all local elements in one loop (equivalent to a single workset). Be aware that this can result in a possibly large performance hit.
Phalanx, in fact, does not restrict you to cell based iteration. You can iterate over any entity type such as edge or face structures.
Consistent Evaluation
Phalanx was imtended to perform consistent evaluations. By consistent, we mean that all dependencies of a field evaluation are current with respect to the current degree of freedom values. For example, suppose we need to evaluate the the energy flux. This has dependencies on the diffusivity, and the temperature gradient. Each of these quantities in turn depends on the temperature. So before the diffusivity and temperature gradient are evaluated, the temperature must be evaluated. Before the energy flux can be evaluated, the density, diffusivity, and temperature gradient must be evaluated. Phalanx forces an ordered evaluation that updates fields in order to maintain consistency of the dependency chain. Without this, one might end up with lagged values being used from a previous evaluate call.
This does not rule out the use of semi-implicit or operator split schemes. In fact these have been demonstrated in Phalanx. It just rquires that users store any lagged history and provide a field evaluator to pull that history in.
Scalar Type
A scalar type, typically the template argument ScalarT in Phalanx code, is the type of scalar used in an evaluation. It is typically a double or float, but can be special object types for extended precision, complex values, and special embedded methods data types such as sensitivity analysis. For example, for sensitivity analysis, a double scalar type is replaced with a foward automatic differentiation object (FAD) or a reverse automatic differentaion object (RAD) to produce sensitivity information. Whatever type is used, the standard mathematical operators are overloaded for the particular embedded technology. For an example of this, see the Sacado Automatic Differentiation Library. Some sample scalar types include:
Data Type
The data type is a deprecated concept used in the original Phalanx implementation. It is now equivalent to the scalar type. You might see use older code specifying a DataT template parameter, but this is now equivalent the ScalarT template parameter.
Evaluation Type
The evaluation type, typically the template argument EvalT in Phalanx code, defines a unique type of evaluation to perform. The user is free to choose/create the evaluation types - they implement their own class or struct for their own evaluation types. An EvaluationContainer is allocated for each evaluation type specified in the users traits class. Examples that we usually use include:
The evaluation type must be associated with one default scalar type and can optionally support additional scalar types. The scalar type usually determines what is being evaluated. For example, to evaluate the equation residuals, the scalar type is usually a double, a float or an extended precision type. To evaluate a Jacobian, the scalar type could be a forward automatic differentiation object, Sacado::Fad::DFAD<double>. By introducing the evaluation type in Phalanx, the same scalar type can be used for different evaluation types and can be specialized accordingly. For example computing the Jacobian and computing parameter sensitivities both could use the Sacado::Fad::DFAD<double> scalar type.
Storage
A DataContainer object stores all fields of a particular data type. Each EvaluationContainer holds a vector of DataContainers, one DataContainer for each vaid data type that is associated with that particular evaluation type. One EvaluationContainer is constructed for each evaluation type.
NOTE: this concept was needed for memory allocation in the first generation Phalanx library when all fields for an evaluation type were stored contiguously in memory. Since the Kokkos transition, memory in now controlled by the Kokkos::View. We could remove this concept and corresponding code in the future. This object is not used by the user and is an underlying implementatino detail. It's removal will NOT result in changes to user code.
Data Layout
The DataLayout object is used to define layout of the multidimensional array used to store Phalanx Fields. It provides the size of each rank in the multidimensional array and provides a unique string name to distinguish fields with the same name that might exist on different layouts. For example, supposed we have written an evaluator the computes the "Density" field for a set of points in the cell. Now we want to evaluate the density at a different set of points in the cell. We might have a "Density" field in a cell associated with a set of integration points (quadrature/integration points in finite elements) and another field associated with the nodes (nodal basis degree of freedom points in finite elements). We use the same field name (so we can reuse the same Evaluator), "Density", but use two different DataLayouts, one for integration points and one for nodal point. Now a FieldTag comparison will differentiate the fields due to the different DataLayout.
Field Tag
The FieldTag is a description of a field. It is templated on the data type, DataT. It is used to identify a field stored in the field manager. It contains a unique identifier (an stl std::string) and a pointer to a data layout object. If two FieldTags are equal, the DataLayout, the data type, and the string name are exactly the same.
Field
A Field is a set of values for a particular quantity of interest that must be evaluated. It is templated on the data type, DataT. It consists of a FieldTag and a reference counted smart pointer (Teuchos::RCP<DataT>) to the data array where the values are stored.
Evaluator
An Evaluator is an object that evaluates a set of Fields. It contains two vectors of Fields, one set is the fields it will evaluate and one set is the fields it depends on for the evaluation. For example to evaluate a density field that is a function of temperature and pressure, the field the evaluator will evaluate (the first field set) is a density field, and the set of fields it requires to meet its dependencies are the temperature and pressure fields (the second field set). The evaluator is templated on the evaluation type and the traits class.
Evaluator Manager
The main object that stores all Fields and Evaluators. The evaluator manager (EM) sorts the evaluators and determines which evaluators to call and the order necessary to ensure consistency in the fields. The EM also allocates the memory for storage of all fields so that if we want to force all fields to be in a contiguous block, we have that option available. Users can write their own allocator for memory management.
Multidimensional Array
Instead of using the concept of an algebraic type that the user implements, it may be easier to use a multidimensional array. For example, suppose we have ten cells, and in each cell there are four points (specifically quadrature points) where we want to store a 3x3 matrix for the stress tensor. Using the concepts of algebraic types, we would use a user defined matrix in a Phalanx Field:
However, Phalanx also implements the idea of a multidimensional array with optional compile time checking on rank accessors.
Here, the "Cell", "QP", and "Dim" objects are small structs that allow users to describe the ordinates associated with the multidimensional array.
The benefits of using the multidimensional array are that (1) checking of the rank accessor at either compile time or runtime (runtime checking is only enabled for debug builds for efficiency) prevent coding errors and (2) the documentation of the ordinals is built into the code - no relying on comments that go out of date.
The EnergyFlux example is reimplemented using the multidimensional array instead of the algebric types in the directory Trilinos/packages/phalanx/example/MultiDimensionalArray/.
Our recomendation is to use the multidimensional array version as future codes plan to use this object. The PHX::MDField is fully compatible with Intrepid whereas the PHX::Field is not. We keep the PHX::Field object around for performance measurements since it directly accesses the Teuchos::ArrayRCP object where the PHX::MDField uses a shards::Array object. If the compiler optimizes correctly, there should be no difference in performance. By testing both the Field and MDField, we can test compiler optimization.
Some recomendations for efficient code:
Use worksets This may eliminate cache misses.
Enable compiler optimization: The Field and MDField classes use inlined bracket operators for data access. That means if you build without optimization some compilers will produce very slow code. To see if your compiler is optimizing away the bracket operator overhead, run the test found in the directory "phalanx/test/Performance/BracketOperator". If the timings are the same between a raw pointer array and the Field and MDField classes, your compiler has removed the overhead. For example, on gnu g++ 4.2.4, compiling with -O0 shows approximately 2x overhead for bracket accessors, while -O2 shows about a 10% overhead, while -O3 completely removes the overhead.
Algebraic Types: Implementing your own algebraic types, while convenient for users, can introduce overhead as opposed to using raw arrays or the multidimensional array. The tests found in "phalanx/test/Performance/AlgebraicTypes" demonstrate some of this overhead. Expression templates should remove this overhead, but in our experience, this seems to be very compiler and implementation dependent. If you build in tvmet support, you can compare expression templates, our "dumb" implementation for vectors and matrices, and our multidimensional array against raw array access. Our testing on gnu compilers shows an overhead of about 20-25% when using "dumb" objects and the expresion templates as opposed to raw arrays. We recommend using raw arrays with the multi-dimensional array (MDField) for fastest runtimes.
Use Contiguous Allocator: Phalanx has two allocators, one that uses the "new" command for each separate field, and one that allocates a single contiguous array for ALL fields. If cache performance is the limiting factor, the contiguous allocator could have a big effect on performance. Additionally, alignment issues can play a part in the allocators depending on how you implement your algrbraic types. Our ContiguousAllocator allows users to choose the alignment based on a template parameter. Typically, this is double.
Limit the number of Fields and/or Evaluators: The more evaluators used in your code, the more the loop sturcutre is broken up. You go from a single loop to a bunch of small loops. This can have an effect on the overall performance. Users should also be judicious on choosing Fields. Only select Fields as a place to introduce variability in your models or for reuse. For example, if you require density in a single place in the code and there is only one single model that won't change, do not make it a field. Just evaluate it once where needed. But if you need density in multiple providers or you want to swap models at runtime, then it should be a field. This prevents having to recompute the model or recompile your code to switch models. This is usually not an issue as long as the amount of work in each evaluator is larger than vtable lookup to make the evaluate call. In our experience, we have never observed this behaviour. We point it our here just in case.
Slow compilation times: As the number of Evaluators in a code grows, the compilation times can become very long. Making even a minor change can result in the code recompiling all Evaluator code. Therefore, we recommend using explicit template instantiation. An example can be found in Trilinos/packages/phalanx/example/FEM_Nonlinear. All evaluators use explicit template instantiation if phalanx is built with explicit template instation enabled (in the cmake build system, use the flag -D Phalanx__EXPLICIT_TEMPLATE_INSTANTIATION=ON).
The multidimensional array was designed for interoperability between a number of Trilinos packages including shards, phalanx and intrepid. These codes each have their own implementations but follow a basic set of requirements so that functions templated on the array type can use any of the multidimensional array implementations. The required functions are:
Phalanx implements the multidimensional array in the PHX::MDField class and supports arrays with up to 8 ranks (one more than Fortran arrays support). More information can be found in the shards library.
Phalanx is distributed as a package in the Trilinos Framework. It can be enabled as part of a trilinos build with the configure option "-D Trilinos_ENABLE_Phalanx=ON". Phalanx currently has direct dependencies on the following third party libraries:
TVMET is optional and hidden behind an ifdef. The performance tests will be built regardless of whether tvmet is enabled/disabled.
To build the example problem in "phalanx/example/FEM_Nonlinear", distributed vector, distributed sparse matrix, and corresponding linear solvers are required. The following Trilinos packages need to be enabled to build the FEM_Nonlinear example:
This example will be disabled if the above packages are not enabled.
The general instructions for building trilinos can be found at Trilinos Documentation Page. Of particular importance are the Overview, User Guide, and Tutorial documents. At a minimum you must enable the Teuchos, Sacado, and Phalanx packages. An example configure script is:
Once configure is run, build and install the library with the command:
Users must next determine the evaluation types and data types they will require in their simulation. Please see the section Phalanx Domain Model for detailed explanation of types. Following the example in the phalanx/example/EnergyFlux directory, we will be requiring two evaluation types, one for the residual evaluation of the discretized PDE equation and one for the corresponding Jacobian. Additional evaluation types might be for the parameter sensitivites and uncertainty quantification.
Once the evaluation types are chosen, users must decide on a default scalar type and on all data types that are valid for each evaluation type. The data types should all be templated on the default scalar type for the particular evaluation type, but this is not a requirement (expert users can violate this for performance reasons). Uses must implement their own data types or get them from a separate library. For sensitivities, the trilinos package Sacado should be used. For uncertainty quantification, the Trilinos package Stokhos should be used.
In our example, the user has written an implementation of vector (MyVector) and matrix (MyTensor) classes found in the file AlgebraicTypes.hpp. They are templated on a scalar type and can be used for all evaluation types.
Typical examples of algebraic types include vectors, matrices, or higher order tensor objects, but in reality can be any struct/class that the user desires. Remember to template the objects on the scalar type if possible. An example of a very inefficient Vector and Matrix implementation (operator overloading without expression templates) can be found in AlgebraicTypes.hpp.
The Traits object is a struct that defines the evaluation types, the data types for each evaluation type, the allocator type, and the user defined types that will be passed through evaluator calls. We will go through each of these defninitions.
The basic class should derive from the PHX::TraitsBase object.
The Traits struct must define each of the following typedef members of the struct:
The basic outline of the traits struct is:
Inside this struct we need to implement all the typedefs listed above. The example we will follow is in the file Traits.hpp in "phalanx/example/EnergyFlux" directory.
First we need to know the evaluation types. Each evaluation type must include at least a typedef'd default scalar type argument as a public member called ScalarT. Here is the example code:
The typedefs RealType and FadType are done only for convenience. They are not actually required but cut down on the typing. Only the EvalTypes typedef is required in the code above.
Next we need to link the data types to the evaluation type. Note that one could use the same data type in multiple evaluation types:
Define the Allocator type to use. Phalanx comes with two allocators, but the user can write their own allocator class if these aren't sufficient. The Phalanx allocator classes are:
Code using the NewAllocator is:
Users can pass their own data to the postRegistrationSetup(), evaluateFields(), preEvaluate() and postEvaluate() methods of the PHX::FiledManager class. In this example, the user passes in a struct that they have written called MyEvalData. This contains information about the cell workset. The user is not required to write their own object. They could just pass in a null pointer if they don't need auxiliary information passed into the routine. This is demonstrated in the SetupSetup, PreEvalData, and PostEvalData. A void* is set for the data member.
For debugging information, Phalanx makes a forward declaration of the PHX::TypeString object. This must be specialized for each evaluation type and each data type so that if there is a run-time error, phalanx can report detailed information on the problem. We could have used the typeinfo from the stl, but the name() method is not demangled on every platform, so it can make debugging a challenge. The specialized classes can go into their own file or can be added to the traits file above depending on how you use the Traits class. During linking, if the compiler complains about multiple defninitions of your specialized traits classes, separate the traits implementation into their own .cpp file.
Before Writing your evaluators, you must decide on how you plan to build the evaluators. In most cases you will want to build one Evaluator for each evaluation type. Phalanx provides an automated factory called the PHX::EvaluatorFactory that will build an evaluator for each evaluation type automatically, but this places a restriction on the constructor of all evaluators built this way. If you plan to use the automated builder, the constructor for the Evaluator must contain only one argument - a Teuchos::ParameterList. This paramter list must contain a key called "Type" with an integer value corresponding to the type of Evaluator object to build. The parameterlist can contain any other information the user requires for proper construction of the Evaluator. You are not restricted to using the automated factory for every Evaluator. You can selectively use the automated factory where convenient.
For each field, you will need an evaluator. Evaluators can evlauate multiple fields at the same time. You can derive from the base class PHX::Evaluator, or you can derive from class PHX::EvaluatorWithBaseImpl that has most of the methods already implemented so that the same support code is not replicted in each evaluator. We STRONGLY recommend deriving from the class PHX::EvaluatorWithBaseImpl.
An example for evaluating the density field is:
Note that if you want to use the automated factory PHX::EvaluatorFactory to build an object of each evaluation type, you must derive from the PHX::EvaluatorDerived class as shown in the example above. This allows the variable manager to store a vector of base object pointers for each evaluation type in a single stl vector.
Also note that we pull the scalar type, ScalarT, out of the evaluation type.
The implementation is just as simple:
The constructor pulls out data from the parameter list to set the correct data layout. Additionally, it tells the FieldManager what fields it will evaluate and what fields it requires/depends on to perform the evaluation.
The postRegistrationSetup method gets pointers from the FieldManager to the array for storing data for each particular field.
Writing evaluators can be tedious. We have invested much time in minimizing the amount of code a user writes for a new evaluator. Our experience is that you can literally have hundreds of evaluators. So we have added macros to hide the boilerplate code in each evaluator. Not only does this streamline/condense the code, but it also hides much of the templating. So if your user base is uncomfortable with C++ templates, the macro definitions could be very helpful. The definitions are found in the file Phalanx_Evaluator_Macros.hpp. The same evaluator shown above is now implemented using the macro definitions:
Class declaration:
Class definition:
The evaluators for the example problem in "phalanx/example/EnergyFlux" have been rewritten using the macro definitions and can be found in the directory "phalanx/test/Utilities/evaluators".
Finally, since writing even the above code contains much boilerplate, we have written a python script that will generate the above skeleton files for you. All you need provide is the class name and the filename. The script is called phalanx_create_evaluator.py and can be found in the "scripts" directory. A "make install" will place the script in the "bin" directory. To generate a skeleton for the above function, you would execute the following command at the prompt:
Adding the FieldManager to your code is broken into steps. You must build each Evaluator for each field type, register the evaluators with the FieldManager, and then call the evaluate routines. Continuing from our example:
Users can build their own Evaluators and register them with the FieldManager or they can use our automated factory, PHX::EvaluatorFactory to handle this for them. Normally, users will want to build an evaluator for each evaluation type. The factory makes this very easy. Additionally, you are not restricted to using the automated factory for every Evaluator. You can selectively use the automated factory where convenient. The next two sections describe how to build the evaluators.
To build an Evaluator manually, all you need to do is allocate the Evaluator on the heap using a reference counted smart pointer (Teuchos::RCP) to point ot the object. This will ensure proper memory management of the object. Here is an example of code to build a Density evaluator for each evaluation type and register it with the corresponding manager.
As one can see, this becomes very tedious if there are many evaluation types. It is much better to use the automated factory to build one for each evalaution type. Where this method is useful is if you are in a class already templated on the evaluation type, and would like to build and register an evaluator in that peice of code.
Phalanx provides an automated builder PHX::EvaluatorFactory that will create an object of each evaluation type. The following requirements are placed on each and every Evaluator that a user writes if they plan to use the automated factory:
The constructor of your Evaluator must take exactly one argument that is a Teuchos::ParamterList object. A Teuchos::ParameterList allows you to pass an arbitrary number of objects with arbitrary types.
In the Teuchos::ParamterList, you must have one key called "Type" that is associated with an integer value that uniquely corresponds to an Evaluator object written by the user. This integer is defined in the users factory traits object described below.
The Evaluator must derive from the PHX::EvaluatorDerived class as shown in the example above. This allows the variable manager to store a vector of base object pointers for each evaluation type in a single stl vector yet be able to return the derived class.
To build an PHX::EvaluatorFactory, you must provide a factory traits class that gives the factory a list of its evaluator types. An example of the factory traits class is the FactoryTraits object in the file FactoryTraits.hpp:
Since the factory is built at compile time, we need to link a run-time choice to the compile-time list of object types. Thus the user must provide the static const int identifiers that are unique for each type that can be constructed. Users can ignore the "_" argument in the mpl vector. This is a placeholder argument that allows us to iterate over and instert each evaluation type into the factory traits.
Now let's build the evaluators. The following code can be found in the Example.cpp file in the directory "phalanx/example/EnergyFlux". We create a ParameterList for each evaluator and call the factory constructor. Since we are using the factory, we need to specify the "Type" argument set to the integer of the corresponding Evaluator in the factory traits that we wish to build:
The map "evaluators_to_build" has a key of type "std::string". This key is irrelevant to the execution of the code. It is an identifer that can help users debug code or search for a specific provider in the list. What you put in the key is for your own use.
You are free to register evaluators until the time you call the method postRegistrationSetup() on the field manager. Once this is called, you can not register any more evaluators. You can make multiple registration calls to add more providers - there is no limit on the number of calls.
You must tell the FieldManager which quantities it should evaluate. This step can occur before, after, or in-between the registration of Evaluators. You must request variables separately for each evaluation type. This is required since since data types can exist in multiple evaluation types.
You are free to request fields to evaluate until the time you call the method postRegistrationSetup() on the field manager. Once this is called, you can not request any more fields.
Once the evaluators are registered with the FieldManager and it knows which field it needs to provide, call the postRegistrationSetup() method on the FieldManager. This method requires that the user specify the maximum number of cells for each evaluation - the workset size. This number should be selected so that all fields can fit in the cache of the processor if possible.
The postRegistrationSetup() method causes the following actions to take place in the FieldManager:
Note: you can no longer register evaluators or request fields to evaluate once postRegistrationSetup() method is called.
If the user plans to use worksets, these objects are typically passed in through the member of the evaluate call as defined in your traits class. In our example, we chose to pass a user defined class called a MyWorkset in to the evaluate call. Since we plan to use worksets, each object of MyWorkset contains information about the workset. Here is the MyWorkset implementation:
The user has written a MyCell class that contains data for each specific local cell. MyWorkset contains iterators to the beginning and end of the chunk of cells for this particular workset. The local_offset is the starting index into the local cell array. The num_cells is the number of cells in the workset. The MyWorkset objects are created one for each workset via the following code:
Note that you do not have to use the workset idea. You could just pass in workset size equal to the number of local cells on the processor or you could use a workset size of one cell and wrap the evaluate call in a loop over the number of cells. Be aware that this can result in a possible performance hit.
Finally, users can call the evlauate routines and the pre/post evaluate routines if required.
Accessing field data is achieved as follows:
You do not need to use the Field objects to access field data. You can get the reference counted smart pointer to the data array directly by using the field tag:
 1.8.5
1.8.5

